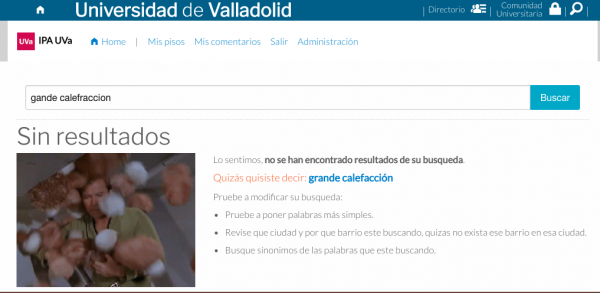
Lo sabemos, seguro que usas Google para tus búsquedas. ¡por supuesto!. Y por eso seguro que te ha impresionado el ver «quizás quiso decir» o ahora que busca resultados de tus búsquedas con las palabras bien escritas. Vamos, que es «a prueba de disléxicos». Pero, como dicen en cierto programa de TV: ¿Cómo lo hacen?.
Antes de hacerlo
Antes de contaros una forma de hacerlo sencilla y fácil que, se puede mejorar es bueno saber que necesitas para hacerlo.
En nuestra forma de hacerlo necesitas un backend de PHP y un frontend de javascript (en el ejemplo usamos React, pero puedes hacerlo en vanilla javascript sin mucho problema si entiendes el como).
La idea
La idea es muy sencilla:
- Coge una frase
- Separar las palabras de la frase
- Comparar cada una de las palabras con algo que este bien escrito
- Si se aproxima mucho lo bien escrito con lo escrito, se pone la palabra buena
Con lo cual, veis que hay dos problemas. Primero el separar las palabras de la frase y, segundo, comparar de alguna forma dichas palabras con algo bueno y que sea capaz de decirte si es parecido o no. Nada más.
El backend
En mi ejemplo he usado un backend de PHP, primero porque yo soy un backend de PHP y segundo (y más importante) porque PHP tiene un «truco» para comprar palabras que hace que el desarrollo se pueda hacer más rápido. Y, por tercero y ultimo, porque la aplicación que lo va a soportar esta (el backend) en PHP 🙂
Ademas, deberas tener una base de datos o ficheros (con el formato que mas te interese, JSON, plano, XML, da igual) o incluso incorporar arrays de tamaño XXL. Todo esto dependerá de tu aplicación y la infraestructura donde lo montes.
El frontend
Todo se puede hacer desde el backend pero, para ser moderno y tener cierta calidad (en la aplicación y en el software que se desarrolla, aparte de que el tiempo de servidor es más caro que el tiempo de cliente) hay una pequeña (enana) parte echa en el front. Debido a que estoy refactorizando la aplicación a React, he usado esta librería de JS.
Como se hizo
Primero veamos la parte del back en PHP. En el fichero PHP lo primero que debemos hacer es pillar (por post o por get) la query, el texto en si para analizar. En mi caso he hecho una librería para Codeigniter llamada analizadorsintactico.php para ciertos métodos.
En el area web usamos, para algunos desarrollos internos Codeigniter como framework.
Os pongo parte del controlador (no del todo):
public function busqueda() {
// Function that takes a query, process it, make a search and return a JSON
$datos["q"] = $this -> input -> post_get('q');
// We take out the words of the query
$datos["palabrasQuery"] = $this -> analizadorsintactico -> queryTexto($datos["q"]);
// Database of nice words
$palabrasBD = $this -> palabras_model -> devuelvePalabras();
// Words "maybe you meant"
$datos["palabrasQueryQuisoDecir"] = $this -> analizadorsintactico -> similitudes_palabras($datos["palabrasQuery"], $palabrasBD);
// Do the search using (in this case) a model who return the results
$datos["resultados"] = $this -> buscador_model -> realizeQuery($datos["palabrasQuery"];
// Changing the header of the response to JSON
header('Content-Type: application/json');
// Print the data JSON encoded
echo json_encode($datos);
}Como vemos, primero hacemos un get o un post que captura el texto. Luego lo limpiamos, es decir, eliminamos muchas cosas usadas en el lenguaje natural (pronombres, artículos, etc…) y la mejor forma de hacerlo… con una expresión regular.
Así que el analizadorsintactico.php incorpora esta función que elimina todo esto.
function queryTexto($string) {
// Method that returns an array with all the words separated or false if not
// Create the empty response array
$trozos = array();
// Using a regular expresion for cleaning the string (spanish language)
$textoSinMierda = preg_replace("/(\b(a|e|o|u)\ )|(\ben\b)|(\bun\b)|(\bde(\b|l))|(\bqu(|é|e)\b)|(\b(a|e)l\b)|(\bell(o|a)(\b|s))|(\bla(\b|s))|(\blo(\b|s))|(\bante\b)|(\bo\b)|(\by\b)|(\bes\b)|(\bsu\b)|(\,|\.|\;)/", "", $string);
// Now we "explode the words"
$trozostmp2 = explode(" ", $textoSinMierda);
// Because user can put double white space we do this!
foreach ($trozostmp2 as $cacho) {
if ($cacho != "") {
// If it's not a white space we add into an array
array_push($trozos, $cacho);
}
}
// Then return the new array of words
return $trozos;
}
// if not, always return false
return false;
}Lo siguiente (volviendo al controlador, no a la librería), coger las palabras de la base de datos, las palabras bien escritas. Como Codeigniter el model MVC (normal), el acceso y la recuperación de las palabras se hace a través de un modelo, esto me lo salto porque me imagino al lector lo suficientemente inteligente para hacerlo.
Después, volvemos a llamar a la librería analizadorsintactico.php para comprar el array de las palabras sacada de la base de datos con las palabras de la query. Así que, volvamos a analizadorsintactico.php.
function similitudes($arrayDatos, $arrayConQuienComparar) {
// Method that search for similar words
// Return an array with the similar words in the same order
// Need a private method call similitudes_sale
// First the return array
$returnArray = array();
// We go through the array
foreach($arrayDatos as $rowCiudadesBusqueda) {
// Test if it's empty because... who knows
if ($rowCiudadesBusqueda != '') {
// For everyone
foreach($arrayConQuienComparar as $rowCiudadesArray) {
// We made the Levenshtein comparation in our private method
$resulttmp = $this -> similitudes_sale($rowCiudadesArray, $rowCiudadesBusqueda);
// Another test... test if it's empty again
if ($resulttmp !='') {
// If not, pushing the array
array_push($returnArray, $this -> similitudes_sale($rowCiudadesArray, $rowCiudadesBusqueda));
}
}
}
}
// The return. This can be done better, I know
if (empty($returnArray) == false) {
// There's data
return $returnArray;
}
// There's no data
return false;
}
private function similitudes_sale($origen, $destino) {
// Function that return the word if it's a 65% (or more) equal using the Levenshtein test// if not, it returns false
$sim = similar_text(strtoupper($origen), strtoupper($destino), $perc);
if ($perc > 65) {
return $origen;
} else {
return false;
}
}Y aquí esta lo bueno, usamos la distancia de Levensthtein entre palabras, si el grado de similitud es mayor del 65% devolvemos la palabra bien escrita.
La distancia de Levensthtein no es más que el número máximo de cambios que hay que realizar (de letras) en una palabra para convertirla en otra. PHP dispone de la función similar_text que, primero, es muy rápida y, segundo, nos devuelve un tanto por ciento de similitud. Así que, ¿por que no usar este «truco»?.
que, primero, es muy rápida y, segundo, nos devuelve un tanto por ciento de similitud. Así que, ¿por qué no usar este «truco»?.
Si usáis otros lenguajes de programación en el backend seguramente u os podéis «montar» vuestra función similar_text o seguramente haya alguna librería con algo parecido que os ayudara bastante.
Aun con todo, una mejora de esta función seria añadir un tanto por ciento variable para diferentes palabras (que puede estar en la base de datos) puesto que el tanto por ciento de similitud varia entre palabras. Pero esto os lo dejo a vosotros.
Y, para finalizar en el controlador, enviarlo todo a la vista que contiene el Javascript con el que trabajar en el cliente gracias a la librería de React para la visualización y un poco de lógica extra. En mi caso, lo que devuelve es un JSON que recoge la vista a través de React.
On the stage
El frontend es muy sencillo gracias a que todo el trabajo duro se ha hecho en el backend (por eso cuando se plantean estas cosas a gran escala se usan granjas y clusters, debido a que funciones como similar_text consumen mucha CPU).
Como usamos React, primero hacemos el fetch en ComponentWillMount(), que es lo que llama la búsqueda, recoge los datos del controlador y actualiza los estados del componente en cuestión.
componentWillMount() {
// We take the query from the URL
let datosBusqueda = window.location.search.substring(1).split('=')[1];
// Decode it, because it's on the URL
datosBusqueda = decodeURIComponent(datosBusqueda);
// Do the fetch man :)
fetch('/index.php/components/busqueda/busqueda?q='+datosBusqueda)
.then((respuesta) => respuesta.json())
.then((respuestaJSON) => {
// Chaging the state of the component
this.setState({
resultados: respuestaJSON.resultados, // results
query: respuestaJSON.q, // query
palabrasQueryArreglada: respuestaJSON.palabrasQueryQuisoDecir, // nice words
isLoading: false // the typical for knowing that it's finish
});
})
.catch((error) => {
// Error!!
alert('Lo sentimos\n\rHa habido un error al realizar la busqueda');
throw 'Error en busqueda: '.error;
});
}Tampoco hay mucho que decir de esto ya que es lo estándar a realizar con un componente que consume datos.
Ahora, en el componente hay que hacer dos cosas (bueno tres). Los resultados (resultados), la query original (query) y la query bien escrita (palabrasQueryArreglada).
Con esto en el estado del componente metido en su sitio podemos componer el «quizás quiso decir» en el render(). Principalmente comparar los dos arrays (el de la query y el de palabrasQueryArregladas).
render() {
[....... other code for your render ........]
// If there's "bad words" that bee good words
var quisoDecir = this.state.query.split(" ");
var quisoDecirRespuesta;
if (this.state.palabrasQueryArreglada.length > 0) {
// We create the new well writen query
quisoDecir = quisoDecir.map((valor, indice) => {
// We go through seen that it's not null
// Creating the return variable that it's false
let retorno = false;
for (let i = 0; i < this.state.palabrasQueryArreglada.length; i++) {
if(this.state.palabrasQueryArreglada[i][valor] !== undefined) {
// If it's not undefined, here is and we must return it
retorno = true;
return this.state.palabrasQueryArreglada[i][valor];
}
}
if (retorno == true) {
// This is not needed but we put here because... you knows...
} else {
// if not, we return the original text
return valor;
}
});
[....... other code for your render ........]
}Recordad que seguro que vosotros lo podéis hacer mejor que yo (por supuesto) y es que lo que hago es ir palabra por palabra por la query original comparandola con la devuelta para ver si esta o no esta la palabra. Y es que en el JSON en la función se devuelve la palabra mal y la buena. Simple.
El futuro
Se puede mejorar de muchísimas formas, una de ellas la que os he comentado antes y es variar el tanto por ciento en cada palabra. Porque el tanto por ciento depende del tamaño de la palabra, de la palabra en si, etc… Esto es lo que hace a Google tan especial ya que internamente usa un analizador por Machine Learning que separa las palabras, ajusta los tantos por ciento y usa CPU a cascoporro. Ventajas de tener dinero.
También podéis implementar y mejorar la base de datos de palabras, el JSON, el array lo que vayáis a usar. Como he indicado, teniendo en cuenta el uso de CPU, vuestra infraestructura, lo que sea.
Otra cuestión es que podéis mejorar la implementación de similar_text de PHP o crearos vuestro propio algoritmo optimizado que mida la distancia de Levensthtein.
Inclusive optimizar la base de datos conteniendo únicamente las palabras necesarias, algoritmos de búsqueda en la base de datos mejorados o un sin fin de cosas.
¡Siempre se puede mejorar! Lo único que os he contado es la idea de como lo hemos montado en un proyecto a sabiendas que esta incluido en una refactorización del mismo.